PDA22 - Proteomics Data Analysis 2022
PDA22 - Proteomics Data Analysis 2022
DESCRIPTION
⚠️ This is an old version of the BioData.pt website, available for reference purposes. Information is out-of-date and some features may not work correctly. Click here to browse the current website.

DESCRIPTION

DESCRIPTION
GTO is a toolkit to unify pipelines in genomic and proteomic research. GTO is a toolkit for genomics and proteomics, namely for FASTQ, FASTA and SEQ formats, with many complementary tools. The toolkit is for Unix-based systems, built for ultra-fast computations. GTO supports pipes for easy integration with the sub-programs belonging to GTO as well as external tools. GTO works as LEGOs, since it allows the construction of multiple pipelines with many combinations
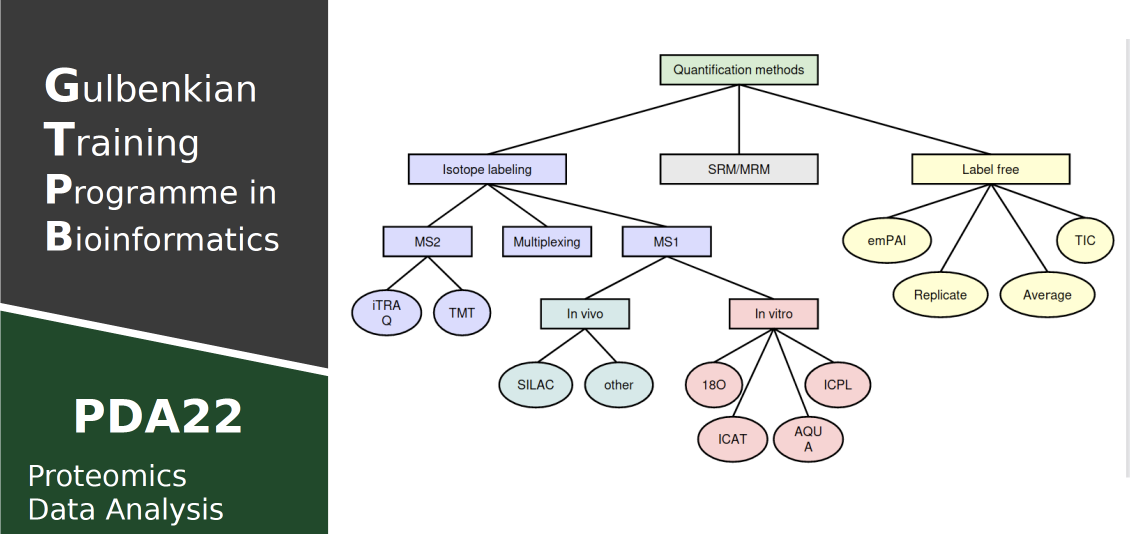
 This training course is aimed at researchers who are not experts in proteomics and want to integrate quantitative proteomics results into wider biomedical experiments. We will focus on quality control from an end-user perspective, link to the underlying genomic context, multivariate analysis, protein complexes investigation, and compare different platforms for biological interpretation.
This training course is aimed at researchers who are not experts in proteomics and want to integrate quantitative proteomics results into wider biomedical experiments. We will focus on quality control from an end-user perspective, link to the underlying genomic context, multivariate analysis, protein complexes investigation, and compare different platforms for biological interpretation.
![]()
![]()
![]()

